With this post I would like to provide an introduction to concepts as Continuous Delivery and Deployment Pipelines, working as an extension for the known Continuous Integration process. This introduction is mostly abstract and "theoretical". The aim is to explain the concepts themselves and explore possible upsides of implementing such patterns in your deployment process.
Continuous Integration
Continuous integration is a well-known engineering practice in agile development that encourages developers to integrate as early and as often as possible. In my early days I remember the facilitation of tools as CruiseControl(.NET) or TFS build servers to enable the Continuous Integration process. Now, especially for .NET developers, Visual Studio Online offers great features and possibilities in a few clicks.
Continuous Integration provides an "official" build location, and developers enjoy the concept of a single mechanism to ensure working code. However, a CI Server also provides a perfect time and place to perform common project tasks such as unit testing, integration testing, code coverage, metrics, functional testing and so on. For many projects, the CI server includes a list of tasks to perform whose successful culmination indicates a build success. Large projects eventually build an impressive list of tasks.
Continuous Delivery
Continuous Delivery describes the deployment pipeline mechanism. Similar to a CI Server, a deployment pipeline "listens" for changes. Then runs a series of verification steps, each with increasing sophistication. We can say that Continuous Delivery is a natural extension of Continuous Integration.
Continuous Delivery practices encourage using a deployment pipeline as the mechanism to automate common project tasks, such as testing, machine provisioning, deployments, etc.
Deployment Pipeline
At an abstract level, a deployment pipeline is an automated manifestation of your process for getting software from version control into the hands of your users.
Deployment pipelines encourage developers to split individual tasks into stages. A deployment pipeline includes the concept of multi-stage builds, allowing developers to model as many post-checkin tasks as necessary. This ability to separate tasks discretely supports the broader mandates expected of a deployment pipeline -to verify production readiness; where as a CI server primarily focuses on integration. Thus, a deployment pipeline commonly includes application testing at multiple levels, automated environment provisioning, and a host of other verification responsibilities.
As such, the deployment pipeline also offers an ideal way to execute the fitness functions defined for an architecture. It applies arbitrary verification criteria, has multiple stages to incorporate different levels of abstraction and sophistication of tests, and runs every single time the system changes in any way.
Usually the first stage of a deployment pipeline will do any compilation and provide binaries for later stages. Later stages may include manual checks, such as any tests that can't be automated. Stages can be automatic, or require human authorization to proceed, they may be parallelized over many machines to speed up the build. Deploying into production is usually the final stage in a pipeline.
An example of this can be visualized:
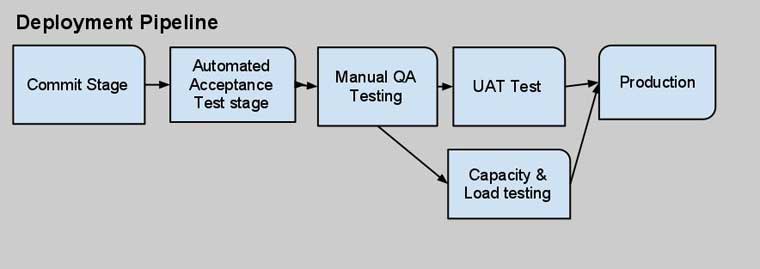
Or a more complex example:
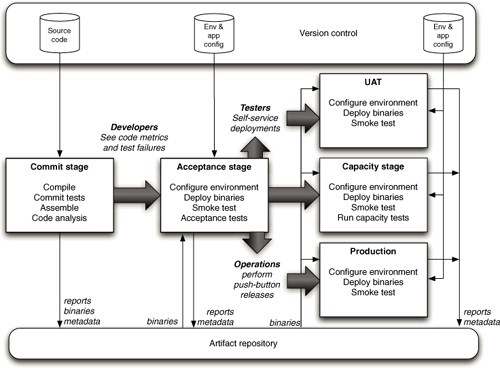
A typical deployment pipeline automatically builds the deployment environment (a container like Docker or a bespoke environment generated by a tool like Puppet or Chef).
By building the deployment image that the deployment pipeline executes, developers and operations have a high degree of confidence. The host computer (or VM) is declaratively defined, and it's common practice to rebuild it from nothing.
For more information see chapter 5 of the Continuous Delivery book, available as a free download.
A very good and easy practical example on utilizing deployment pipelines can be found in the blog-post of @BenjaminTodts here
Comments?
Leave us your opinion.